Text Blocks
- text
- =
- join
- make text
- length
- text<
- text=
- text>
- trim
- upcase
- downcase
- starts at
- contains
- split at first
- split at first of any
- split
- split at any
- split at spaces
- segment
- replace all
text
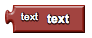
Contains a text string.
equals

Tests whether two given values are equal. If so, returns true; otherwise, returns false. This is the same block found in the logic drawer and is repeated here for convenience. The arguments can be anything, not just text.
join
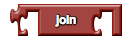
Appends the second given string to the first. For this operation, and all text
operations, numbers can be treated as text. For example, using a join
block to join 1 plus 1 and 2 times 3 results in 26 (2 joined with 6).
make text

Joins all given values into one text string.
length

Returns the length of the given string.
text<
Reports whether the first text string argument is alphabetically less than the second text string. If two strings begin with the same characters, the shorter string is considered smaller. Uppercase characters precede lowercase characters.
text=
Reports whether the text strings are identical, i.e., have the same characters in the same order.
Note that if you are comparing text boxes that contain digits, there is a
difference between comparing them numerically using ordinary equality
(=) versus comparing them as text strings (text=). If you
create two text boxes, one with the characters 123 and one with the
characters 0123, then these will be equal numerically but not equal as
text strings. Be careful that, when it comes to comparisons like this, there is a
difference between entering the digits using number boxes, versus entering them as
text boxes. Suppose you create two number boxes, on with 123 and one
with 0123. If you compare those two boxes using text=
you'll get the result that they are equal. The reason is that the digits you enter
into a number box get converted to a number; the actual string of digits is not
preserved. If you want to take account of the actual string of digits, then use a
text box.
text>
Reports whether the first text string argument is alphabetically greater than the second text string. If two strings begin with the same characters, the shorter string is considered smaller. Uppercase characters precede lowercase characters.
upcase
Returns a copy of its text string argument converted to uppercase.
downcase
Returns a copy of its text string argument converted to lowercase.
trim
Returns a copy of its text string argument with any leading or trailing spaces removed.
starts at

Returns the character position where the first character of piece
first appears in text, or 0 if not present. For example, the location
of ana in havana banana is 4.
contains

Returns true if piece appears in text; otherwise, returns
false.
split at first

Divides the given text into two pieces using the location of the first occurrence
of at as the dividing point, and returns a two-item list consisting of
the piece before the dividing point and the piece after the dividing point.
Splitting apple,banana,cherry,dogfood with a comma as the splitting
point returns a list of two items: the first is the text apple and the
second is the text banana,cherry,dogfood. Notice that the comma after
apple doesn't appear in the result, because that is the dividing point.
split at first of any

Divides the given text into a two-item list, using the location of any item in the list at as the dividing point.
split
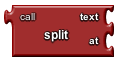
Divides text into pieces using at as the dividing points
and produces a list of the results. Splitting one,two,three,four at
, (comma) returns the list (one two three four).
Splitting one-potato,two-potato,three-potato,four at
-potato, returns the list (one two three four).
split at any

Divides the given text into a list, using any of the items in at as
the dividing point, and returns a list of the results. Splitting
appleberry,banana,cherry,dogfood with at as the
two-element list whose first item is a comma and whose second item is
rry returns a list of four items: (applebe banana che
dogfood)
split at spaces

Divides the given text at any occurrence of a space, producing a list of the pieces.
segment

Extracts part of the text starting at start position and continuing
for length characters.
replace all
Returns a new text string obtained by replacing all occurrences of the substring with the replacement.
